Citation: “Assessing Data Workflows for Common Data ‘Moves’ Across Disciplines” Alan Liu, 6 May 2017. doi: 10.21972/G21593.
This is a slightly revised version of my position paper for the “Always Already Computational: Collections as Data” Forum, UC Santa Barbara, March 1-3, 2017. (The original version is included among a collection of such position statements by participants in the conference.) A further revised version was later published as “Data Moves: Libraries and Data Science Workflows,” in Libraries and Archives in the Digital Age, ed. Susan L. Mizruchi (Cham: Palgrave Macmillan, 2020), 211–19, https://doi.org/10.1007/978-3-030-33373-7_15.
6 May 2017
In considering how library collections can serve as data for a variety of data ingest, transformation, analysis, reproduction, presentation, and circulation purposes, it may be useful to compare examples of data workflows across disciplines to identify common data “moves” as well as points in the data trajectory that are especially in need of library support because they are for a variety of reasons brittle.
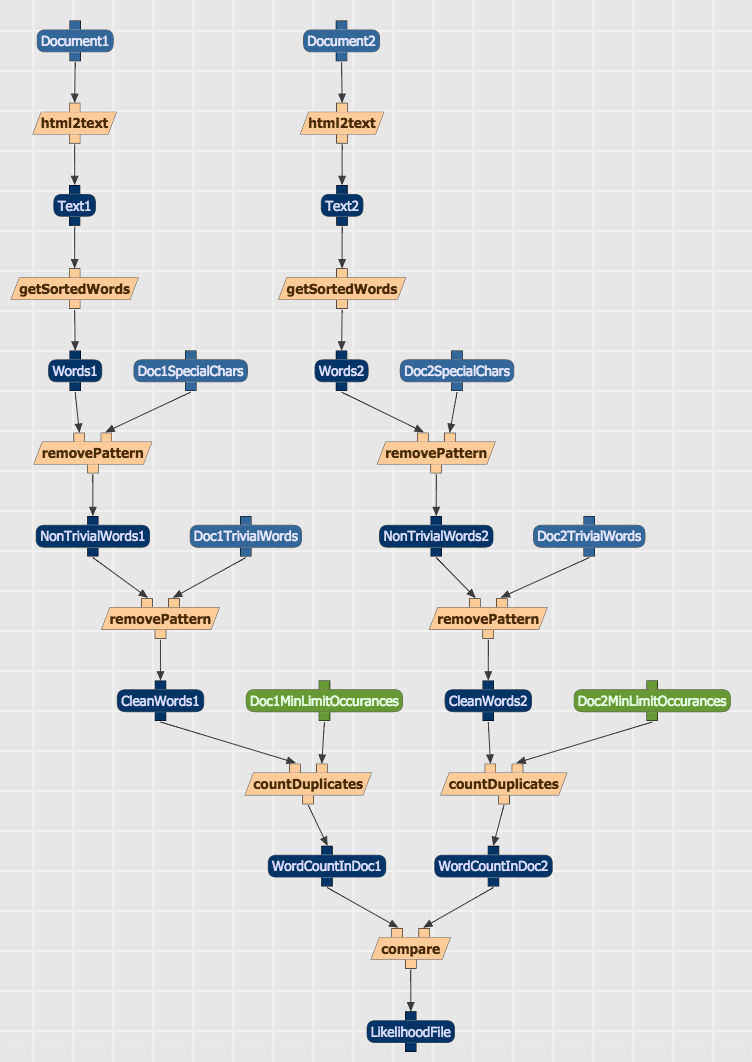
We might take a page from current research on scientific workflows in conjunction with research on data provenance in such workflows. Scientific workflow management is now a whole ecosystem that includes integrated systems and tools for creating, visualizing, manipulating, and sharing workflows (e.g., Wings, Apache Taverna, Kepler, etc.). At the front end, such systems typically model workflows as directed, acyclic network graphs whose nodes represent entities (including data sets and results), activities, processes, algorithms, etc. at many levels of granularity, and whose edges represent causal or logical dependencies (e.g., source, output, derivation, generation, transformation, etc.) (see fig. 1). Data provenance (or “data lineage” as it has also been called in relation to workflows) complements that ecosystem through standards, frameworks, and tools–including the Open Provenance Model (OPM) the W3C’s PROV model, ProvONE, etc. Linked-data provenance models have also been proposed for understanding data-creation and -access histories of relations between “actors, executions, and artifacts.”[1] In the digital humanities, the in-progress “Manifest” workflow management system combines workflow management and provenance systems.[2]
The most advanced research on scientific workflow and provenance now goes beyond the mission of practical implementation to meta-level analyses of workflow and provenance. The most interesting instance I am aware of is a study by Daniel Garijo et al. that analyzes 177 workflows recorded in the Wings and Apache Taverna systems to identify high-level, abstract patterns in the workflows.[3] The study catalogs these patterns as data-oriented motifs (common steps or designs of data retrieval, preparation, movement, cleaning/curation, analysis, visualization, etc.) and workflow-oriented motifs (common steps or designs of “stateful/asynchronous” and “stateless/synchronous” processes, “internal macros,” “human interactions versus computational steps,” “composite workflows,” etc.). Then, the study quantitatively compares the proportions of these motifs in the workflows of different scientific disciplines. For instance, data sorting is much more prevalent in drug discovery research than in other fields, whereas data-input augmentation is overwhelmingly important in astronomy.

Since this usage of the word motifs is unfamiliar, we might use the more common, etymologically related word moves to speak of “data moves” or “workflow moves.” A move connotes a combination of step and form. That is, it is a step implemented not just in any way but in some common way or form. In this regard, the Russian word mov for “motif,” used by the Russian Formalists and Vladimir Propp, nicely backs up the choice of the word move to mean a commonplace data step/form. Indeed, Propp’s diagrammatic analyses of “moves” in folk narratives (see fig. 2) look a lot like scientific workflows. We might even generalize the idea of “workflows” in an interdisciplinary way and say, in the spirit of Propp, that they are actually narratives. Scientists, social scientists, and humanists do not just process data; they are telling data stories, some of which influence the shape of their final narrative (argument, interpretation, conclusion).
The takeaway from all the above is that a comparative study of data workflow and provenance across disciplines (including the sciences, social sciences, humanities, arts) conducted using workflow modeling tools could help identify high-priority “data moves” (patterns of nodes and edges in the workflow graphs) for a library-based “always already computational” framework.
One kind of high priority is likely to be very common data moves. For example, imagine that a comparative study showed that in a sample of in silico or data analysis projects across several disciplines over 40% of the data moves involved R-based or Python-based processing using common packages in similar sequences (perhaps concatenated in Jupyter notebooks); and, moreover, that among this number 60% were common across disciplinary sectors (e.g., science, social science, digital humanities). Then these are clearly data moves to prioritize in planning “always already computational” frameworks and standards.
Another kind of high priority may be data moves that involve a lot of friction in projects or in the movement of data between projects. One simple example pertains to researchers at different universities ingesting data from the “same” proprietary database who are prevented from standardizing live references to the original data because links generated through their different institutions’ access to the databases are different. Friction points of this kind identified through a comparative workflow study are also high value targets for “always already computational” frameworks and standards.
Finally, one other kind of high priority data move deserves attention for a combination of practical and sensitive issues. Many scenarios of data research involve the generation of transient data products (i.e., data that has been transformed at one or more steps of remove from the original data set). A comparative workflow study would identify common kinds of transient data forms that require holding for reasons of reproduction or as supporting evidence for research publications. In addition, because some data sets cannot safely be held because of either intellectual property constraints or sensitive IRB (“institutional review board,” “human subjects research” board) issues, transformed datasets (e.g., converted into “bags of words,” extracted features, anonymized, aggregated, etc.) take on special importance as holdings. A comparative workflow study could help identify high-value kinds of such holdings that could be supported by “always already computational” frameworks and standards.
[1] Hartig, Olaf. “Provenance Information in the Web of Data.” In Proceedings of the Linked Data on the Web Workshop at WWW, edited by Christian Bizer, Tom Heath, Tim Berners-Lee, and Kingsley Idehen, April 20, 2009. http://ceur-ws.org/Vol-538/ldow2009_paper18.pdf.
[2] Kleinman, Scott. Draft Manifest schema. WhatEvery1Says (WE1S) Project, 4Humanities.org.
[3] Garijo, Daniel, Pinar Alper, Khalid Belhajjamey, Oscar Corcho, Yolanda Gil, and Carole Goble. “Common Motifs in Scientific Workflows: An Empirical Analysis.” 2012 IEEE 8th International Conference on E-Science (e-Science), 2012: 1–8. doi: 10.1109/eScience.2012.6404427.
