Citation: “Digital Humanities Diversity as Technical Problem” Alan Liu, 15 January 2018. doi:10.21972/G21T07.
This paper was originally presented 5 January 2018 at MLA 2018, session 347 on “Varieties of Digital Humanities” (Twitter hashtags: #mla18, #s347). The original prompt to panelists (in an email from the organizers) was as follows: “The session corresponds with a planned 2019 special issue of PMLA on the same topic, and the talks at this panel may be published as an edited transcript…. Your talk would be about 10 minutes long, and we’d be interested in hearing your views on what’s next for digital humanities and/or what we can learn from what has come before.”
The below version of my paper is revised to supply notes and to substitute links or references for slide images. Another change: two paragraphs elided at the live event due to lack of time–on “DH Re-imagination of Time-Space” and “Rhetorical DH”–are here included.
Clearly, there are further research directions for “digital humanities diversity as technical problem” to be explored beyond those I sketch here, but these are a beginning agenda.
15 January 2018
Our “Varieties of DH” panel addresses the methodological and social diversity of the digital humanities, in part by drawing on the digital humanities meme of the “big tent,” originally the declared theme of the international DH conference when it was held at Stanford University in 2011.[1] To quote the program description for our panel today, DH is “expansive, movable, but precarious, a tent still not big enough in terms of diversity and access.”[2]
The “big tent” metaphor, of course, comes down to us from old-timey showcases of mass experience such as nineteenth-century tent revivals and big-top circuses. Those were just two of the mass architectures, apparatuses, institutions, and (to use Foucault’s word) dispositifs whose paradoxically open and enclosed forms stage-managed the modernizing encounter (variously democratic, cultic, or fascist) between an older, affinity-based sense of the Volk and the newer awareness–at once enraptured, entertained, and appalled–of social, racial, linguistic, geopolitical, and even “special” in the sense of cross-species) variety.  Circuses, for example, were spectacles of variety. As advertised in a nineteenth-century Barnum & Bailey poster, they are “a glance at the great ethnological congress” and also menagerie of “curious . . . animals.”[3] We can add earlier and later examples to the catalogue of paradoxically open/closed, inclusive/exclusive variety–for instance, the French Revolutionary Champs de Mars, whose remaking for the 1790 Fête of Federation famously convened Parisians both low and high[4]; Albert Speer’s “cathedral of light” (Lichtdom) ringed by searchlights at the Nuremberg Nazi rallies; and today’s conceptual architecture of “open source” programming (not the “cathedral,” Eric Raymond memorably said, but the “bazaar”).[5]
Circuses, for example, were spectacles of variety. As advertised in a nineteenth-century Barnum & Bailey poster, they are “a glance at the great ethnological congress” and also menagerie of “curious . . . animals.”[3] We can add earlier and later examples to the catalogue of paradoxically open/closed, inclusive/exclusive variety–for instance, the French Revolutionary Champs de Mars, whose remaking for the 1790 Fête of Federation famously convened Parisians both low and high[4]; Albert Speer’s “cathedral of light” (Lichtdom) ringed by searchlights at the Nuremberg Nazi rallies; and today’s conceptual architecture of “open source” programming (not the “cathedral,” Eric Raymond memorably said, but the “bazaar”).[5]
What’s next for DH? I think what’s next is finally to put the “big tent” metaphor to rest. We need new paradigms and dispositifs or, in computer-speak, platforms for diversity that move the modern democratic paradox of open and closed (inclusive and exclusive) beyond nineteenth- and early-twentieth-century paradigms of mass “variety,” beyond the mid- to late-twentieth-century scientizing of such variety as statistical socioeconomics, and likely also beyond current “bags of words” cultural analytics approaches, which bring up the rear with topic models and other congregations of language standing in for the big tent (or bag) of mass human experience.
Among other things, in other words, diversity is a technical problem. What’s next is for DH to help make advances in the technical platforms and methods for understanding–and also changing our understanding–of diversity née variety (two words with a common root but increasingly different meanings). That will require collaborating with the social sciences, information science, computer science, in silico STEM sciences, non-profits such as DataKind and ProPublica, and also Silicon Valley industry to foster a virtuous circle in which technical innovation drives the understanding of diversity, and the understanding of diversity drives technical innovation. Inasmuch as DH has a unique, as opposed to follow-on, contribution to make to cultural criticism (about which I asked some years ago)[6], I think the techne of diversity may be it.
Here is a series of idea points (I am myself no longer using the vocabulary of “bullet points”) that instance some of the next-generation technical problems that digital humanists could work on to develop an adequate platform for thinking and practicing diversity:
- Multilingual DH. To study comparative literature, history, and society, the digital humanities need to solve the language problem. Most text analysis, for instance, only works on one language at a time. What methods might instead facilitate the comparison of topic models of English and Spanish corpora, for example? Or, again, might neural-network translation like that now used by Google someday allow DH to text-analyze on-the-fly “interlingua” (machine-generated transitional language forms that are like a pure comparatism)?[7] Research such as that by David Mimno et al. on “Polylingual Topic Models” indicates new approaches in computer science to such issues, which digital humanists should follow up.[8]
- Multimedia DH. As in the case of the HiPSTAS project (High Performance Sound Technologies for Access and Scholarship) or Lev Manovich’s Instagram “direct [data] visualizations,” DH research has begun distant reading the audiovisual record of human experience.[9] But there is much rapidly advancing technical research in this area that could be brought into DH, which is a notoriously text-centric field. Otherwise, the fuller corpora of culture remain out of reach, including those for diverse peoples whose culture, whether past or present, flowers in amplest or most unique form outside text. Again, neural-network artificial intelligence–e.g., as applied to image recognition (the early canonical example being Google’s research on recognizing images of cats)[10]–indicates new horizons. A specific contribution of DH might be to add historical corpora for such research or, again, to work on today’s updated, digital version of the old visual/verbal or ut pictura poesis problem. (For example, what defines an adequate visualization of a textual pattern or, thinking in the other direction, of an adequate label or annotation of a visual pattern?)
- Representative DH Corpora. What is a representative corpus for DH study? We have barely begun to identify measurable facets of “representativeness” (social, political, economic, cultural, linguistic, religious, racial, ethnic, gender-based, and so on) in large collections of texts or other media.[11] Next is to create ways of assessing the balance, and thus diversity, of those facets; representing the absent presence of undercounted, censored, or erased voices; and triangulating the whole notion of a representative corpus with such older paradigms of variously open/closed representativeness as “editions,” “canons,” or (specifically in the corpus linguistics sense) “corpus.” And still next is to create repository, database, and TEI/XML guidelines that facilitate the inclusion and assessment of diversity in curatorial and content management systems. For example, imagine that the prosopographical parts of the TEI P5 guidelines relevant to diversity (after further evolution) could be built into content management systems, thus allowing plug-ins to be created that calculate and display measures of diversity according to optional filters (i.e., points of view about diversity) that are themselves diverse.[12]
- DH Reimagination of Time-Space. The digital humanities offer new paradigms for what Bakhtin called the “chronotope” of the cultural imaginary (or, as he referred to it, “the novel”).[13] Robust branches of DH in history, literature, archaeology, and geography all explore this terrain. Yet those branches barely collaborate today to make possible a cross-DH reinterpretation of such notions as world, nation, locality, period, era, longue durée, trend, movement, generation, individual life, seasonal or diurnal life, event, and today’s computational “micro-temporality” (as media archaeologist Wolfgang Ernst calls it).[14] These are the times and spaces of the human past and present that many DH projects acknowledge only in such throwaway gestures of timespace-thinking as “nineteenth” or “twentieth-century” fiction in “Britain” or “America.” Thinking diversity with next-generation tools will require a consolidated DH effort to reimagine the chronotope so that all the times and spaces where different people live and leave traces behind can be understood with new computationally assisted ways of bringing to view the ineluctable differences and intersections in the chronotopical juggernaut today otherwise called “globalism.” Without such a reimagination, which is also a reimagination of the archive in the age of the network, we would just have to accept the charge that DH is yet another foot solder of the “neoliberal” timespace imaginary[15], in which everything possible to be aggregated ends up in omni-databases that reduce differences to capitalizable status prompts of the sort: “what are you doing right now?”
- Rhetorical DH. So much of the human record (one case: the media articles on the humanities that the Mellon-funded 4Humanities “WhatEvery1Says” project I direct is studying) consists in rhetorical frames in which someone is speaking to or on behalf of someone else–e.g., a politician supposedly speaking for taxpayers or parents. No one speaks alone in a rhetorical vacuum, or in a bag of words. Rhetorical and language-culture research of the kind that writing programs specialize in–for example, in their leading-edge area known as “writing studies”–tune into such dialectical structures on the Internet and elsewhere.[16] So too does media “frame” analysis.[17] DH and rhetoric studies (the latter previously known to DH only as “computers and composition”) need to be reintroduced to each other, and both need to collaborate with sociologists working on social network analysis. That is how DH can begin to understand the full rhetorical complexity of what computational approaches otherwise treat univocally as “text,” “natural language,” or “corpora.” Put simply, it makes a difference–and is constitutive of society as a diverse plenum of representation–who is speaking first (or later) to whom in the hearing of who else. The DH treatment of power structures, for example (and of power-law distributions in social media), will need to be a rhetorical treatment.
- High-dimensional Space DH. Many of the “distant reading” text-analysis methods of the digital humanities (e.g., word collocations, clustering analyses, and topic modeling) operate in so-called “high dimensional” mathematical spaces–conceptual spaces in which, for instance, a word has hundreds of thousands of dimensions each defined by statistical distance to other words. I have previously mentioned neural-network AI in this talk. One leading-edge DH methodology at present is “word embedding,” which uses neural networks to model semantic relations between words in a representation of high-dimensional space (see image from tensorflow visualization of word embedding).[18]
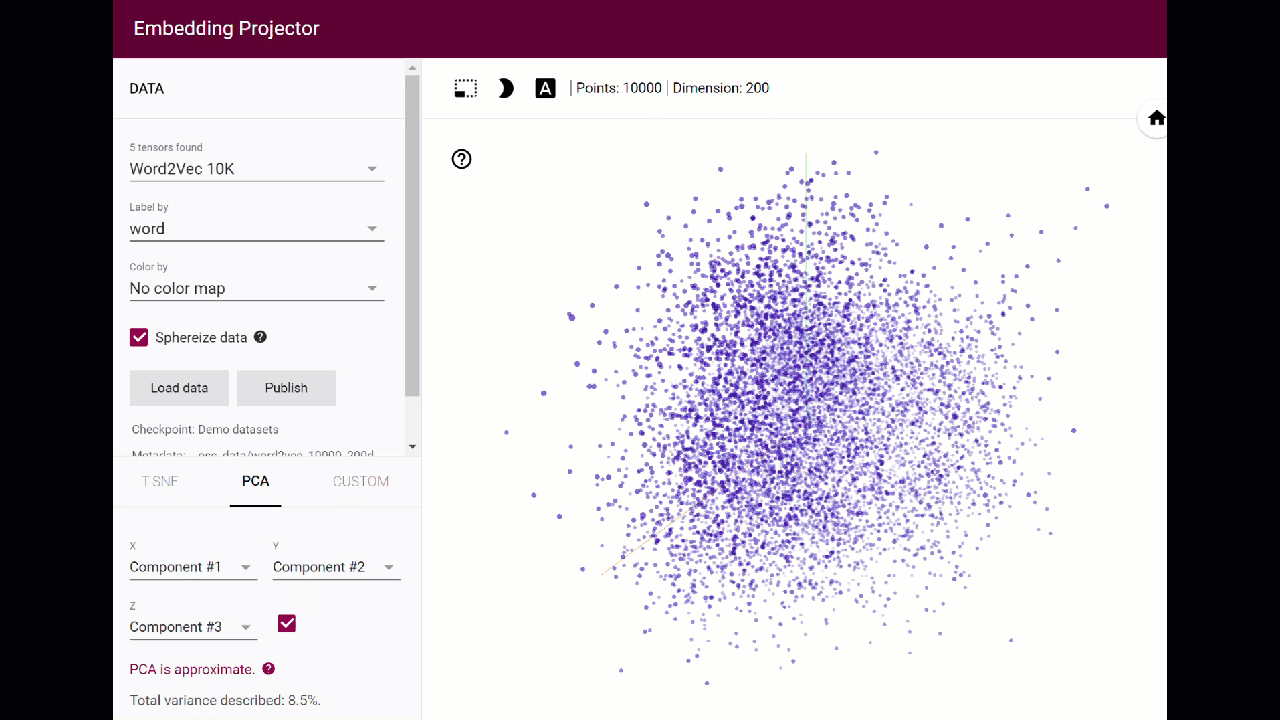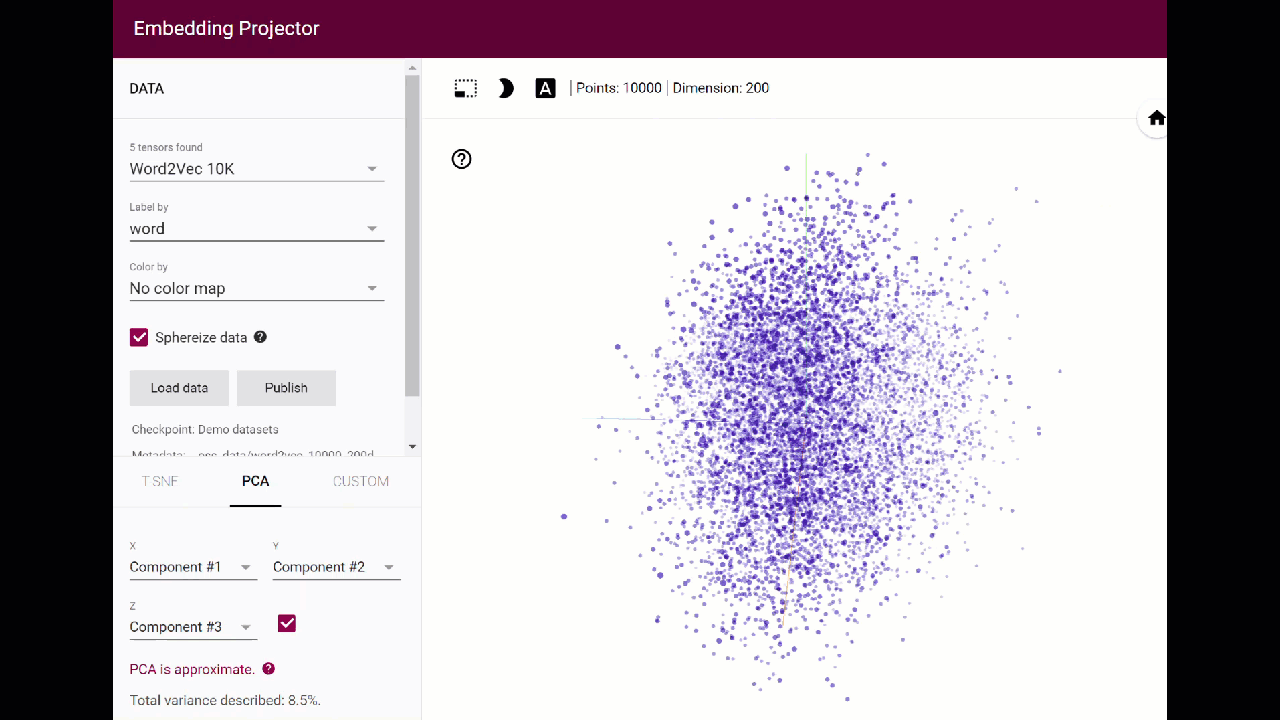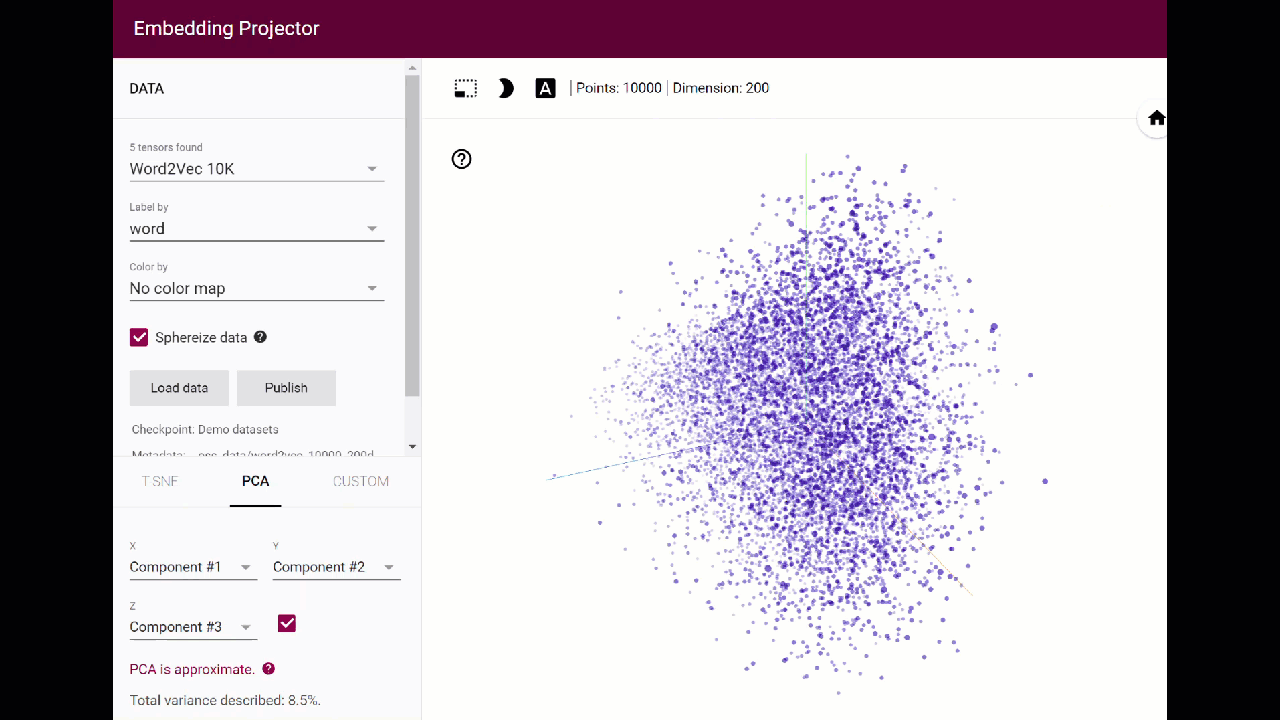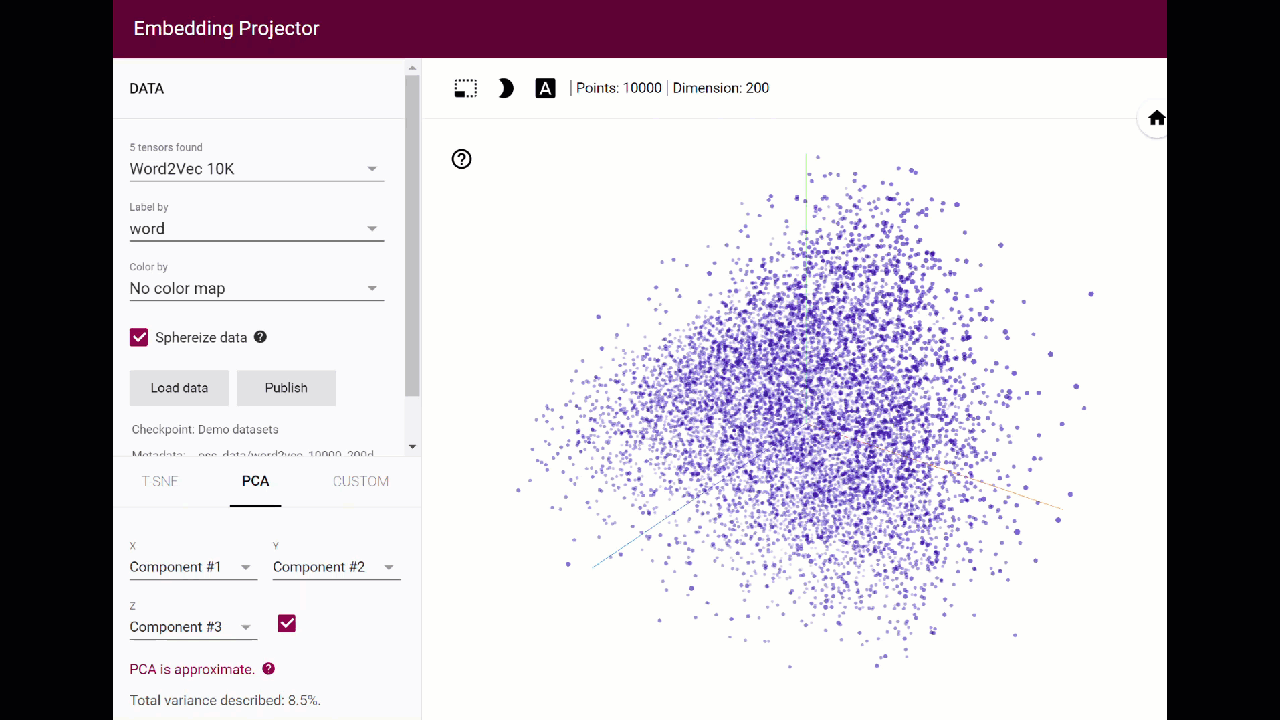 Such models have the uncanny ability to reveal the cultural logic (analogies, for example) implicit in the way we use language, complete with all the cultural biases of that logic. The standard example used to explain word embedding is the computationally-generated answer to the question: “King is to Queen as Man is to [what]?” You can only imagine what analogies other words related to gender, race, ethnicity, nation, religion, age, or class (if queried in the model) will produce. For DH to shed its old-timey “big tent” paradigm for diversity, I believe, it will need to develop new conceptual paradigms based on operations in, understandings of, and, yes, also metaphors for high-dimensional spaces. That is one of the new big tents.
Such models have the uncanny ability to reveal the cultural logic (analogies, for example) implicit in the way we use language, complete with all the cultural biases of that logic. The standard example used to explain word embedding is the computationally-generated answer to the question: “King is to Queen as Man is to [what]?” You can only imagine what analogies other words related to gender, race, ethnicity, nation, religion, age, or class (if queried in the model) will produce. For DH to shed its old-timey “big tent” paradigm for diversity, I believe, it will need to develop new conceptual paradigms based on operations in, understandings of, and, yes, also metaphors for high-dimensional spaces. That is one of the new big tents.
Notes
[1] See Matthew Jockers and Glen Worthey, “Introduction: Welcome to the Big Tent,” n. d., Digital Humanities 2011 Abstracts, http://dh2011abstracts.stanford.edu/xtf/view?docId=tei/ab-005.xml.
[2] “Varieties of Digital Humanities” (session description), Program for MLA 2018, PMLA 132.4 (September 2017): 892. Online version in the Confex conference and abstract management system: https://mla.confex.com/mla/2018/meetingapp.cgi/Session/2517.
[3] The Barnum and Bailey greatest show on earth–A glance at the great ethnological congress and curious led animals…, c. 1895, Library of Congress, http://www.loc.gov/pictures/item/98500053.
[4] Mona Ozouf studied the ideology of openness staged by this arena and other Revolutionary festivals in France in her superb Festivals and the French Revolution, trans. Alan Sheridan (Cambridge, Mass.: Harvard University Press, 1988). See especially her chapter on “The Festival and Space.”
[5] Eric S. Raymond, The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary (Cambridge, MA: O’Reilly, 2001).
[6] Alan Liu, “Where is Cultural Criticism in the Digital Humanities?” Debates in the Digital Humanities, ed. Matthew K. Gold (Minneapolis: University of Minnesota Press, 2012): 490-509. Open-access online version: http://dhdebates.gc.cuny.edu/debates/text/20.
[7] On “interlingua” in Google’s neural-network translation service, see such reports as Devin Coldewey’s “Google’s AI Translation Tool Seems to Have Invented Its Own secret Internal Language,” TechCrunch, 22 November 2016, https://techcrunch.com/2016/11/22/googles-ai-translation-tool-seems-to-have-invented-its-own-secret-internal-language. For an excellent long-form article on Google’s development of its neural-network based translation service, which replaced its older system in 2016, see Gideon Lewis-Kraus, “Going Neural,” New York Times Magazine, 18 December 2016, p. MM40. Online version: “The Great AI Awakening,” 14 December 2016, https://www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html.
[8] Mimno, David, et al. “Polylingual Topic Models.” Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore, 6-7 August 2009, vol. 2: 880-889. Association for Computational Linguistics, 2009. https://dl.acm.org/citation.cfm?id=1699627.
[9] HiPSTAS: High Performance Sound Technologies for Access and Scholarship, home page, n. d., https://blogs.ischool.utexas.edu/hipstas/2012/11/14/welcome-to-hipstas; Lev Manovich, Instagram and Contemporary Image, manovich.net, 2016. http://manovich.net/index.php/projects/instagram-and-contemporary-image. On Manovich’s “direct visualization” method, see also his “What is Visualization?” manovice.net, 2010, http://manovich.net/index.php/projects/what-is-visualization.
[10] See Quoc V. Le, et al., “Building High-Level Features Using Large Scale Unsupervised Learning,” Proceedings of the 29th International Conference on Machine Learning, Edinburgh, Scotland, UK, 2012, https://research.google.com/archive/unsupervised_icml2012.pdf.
[11] The following are examples of facets of “representativeness” in corpora currently being weighted in the 4Humanities.org’s Mellon Foundation funded WhatEvery1Says project, which is gathering and studying a large corpus of media articles and other material discussing the humanities:
- Ownership
- Distribution Method
- Medium
- Format
- Nationality
- Global/National/Local
- Language
- Locality
- Geographical Coverage
- Press Freedom Ranking
- Circulation Size
- Political Orientation
- Cultural Class (e.g., highbrow vs. Tabloid)
[12] See 13.3.2.1 (“Personal Characteristics”) of the TEI P5 Guidelines, TEI Guidelines Version 2.5.0, 26 July 2013, http://www.tei-c.org/Vault/P5/2.5.0/doc/tei-p5-doc/en/html/ND.html#NDPERSE.
[13] M. M. Bakhtin, The Dialogic Imagination: Four Essays, ed. Michael Holquist, trans. Cary Emerson and Michael Holquist (Austin: University of Texas Press, 1981).
[14] Wolfgang Ernst. See, e.g., his “Archives in Transition: Dynamic Media Memories,” in Digital Memory and the Archive, ed. Jussi Parikka (Minneapolis: University of Minnesota Press, 2012): 95-101.
[15] For the critique of the digital humanities I allude to, see Daniel Allington, Sarah Brouillette, and David Golumbia, “Neoliberal Tools (and Archives): A Political History of Digital Humanities,” Los Angeles Review of Books, 1 May 2016., https://lareviewofbooks.org/article/neoliberal-tools-archives-political-history-digital-humanities/.
[16] The Writing Program at my own university provides an excellent definition of “writing studies” on the Web site for its Ph.D. Emphasis in Writing Studies: “Writing Studies is a research-based field broadly focused on analyzing the production, consumption, and circulation of writing in specific contexts. The field incorporates subspecialties such as composition and rhetoric, computers and writing, second language writing, genre studies, and textual analysis…. Writing studies researchers examine the ways in which writing serves to construct and perpetuate communities of practice– academic disciplines, community groups, civic enterprises, or professions. These studies frequently combine multiple research methods, including textual analysis, ethnographic observation and interviews, discourse analysis, and statistical analysis” (“Ph.D. Emphasis in Writing Studies,” Writing Program, University of California, Santa Barbara, 2018, http://www.writing.ucsb.edu/academics/graduate/phd-emphasis).
[17] On “frame” analysis, especially as it has been applied to analysis of journalistic media, see for example, George Lakoff, “Framing 101: How to Take Back Public Discourse,” in Don’t Think of an Elephant!: Know Your Values and Frame the Debate (White River, VT: Chelsea Green, 2004), p. 3-34; and the materials on the site of The FrameWorks Institute, 2018, http://www.frameworksinstitute.org.
[18] Dynamic visualization of Word2Vec, TensorFlow, n. d., http://projector.tensorflow.org/. See documentation page, “Embeddings,” 2 November 2017, https://www.tensorflow.org/programmers_guide/embedding. For an explanation of word embedding, see Benjamin M. Schmidt, “Word Embeddings for the Digital Humanities,” Bookworm (blog), 25 October 2015, http://bookworm.benschmidt.org/posts/2015-10-25-Word-Embeddings.html. [Note: there are scripts running on this page that may cause a browser to freeze temporarily. If a browser dialogue pops up, choose to “continue” until the page fully loads.]

{kind=link}